
Where Data Engineering Is Heading in 2026 - 5+ Trends
The Weekend Windup #21 - Reflections, Cool Reads, Events, and More

A big reason why I don’t like to do annual predictions is that I don’t usually have the data to make an assessment. I can make up some clickbait guesses, but that’s not me. And too often, these assessments are very wrong. That’s why I don’t make specific end-of-year or beginning-of-year predictions for data engineering in 2026.
But…I also did something behind the scenes that I just unveiled this week: collecting data from 1,101 data practitioners and leaders. Now, I have a better sense of where we’re going, at least as of February 2026. And here’s where I think data engineering is going in 2026, or at least my best guess as of now.
The Big Picture
The problems that plagued us for ages continue to plague us today: lack of leadership, unclear ownership, technical debt, time pressures, etc. Based on what I’m seeing elsewhere, the continued acceleration of AI will only exacerbate this problem. Ironically, AI might also improve the problem as it takes on more and more behind the scenes work, assuming we still have jobs by then. But that all remains to be seen.
Data engineering is diverging into two tracks: teams that invested in foundational work and those that didn’t. I think as the year continues, this gap will widen. I will some pulse surveys on this and other topics through the year.
Data modeling, or lack thereof, is a big deal. The big tell is that 38% of ad-hoc modelers are fighting fires vs. those with a data modeling approach in place, who fight fewer fires. I think this is a preview of things to come, and AI tools will accelerate both paths. Disciplined teams will use AI to move faster with quality. Undisciplined teams will use AI to create technical debt faster.
The big theme of 2026 is that unpaid debts of the past carry interest, accruing at payday loan rates. Nothing is free, and payment is due son.
Let’s get a bit more granular and look at the five trends I see.
Five Trends I See in Data Engineering (and More)
1. Ignore AI at Your Peril
According to the survey, 82% daily usage means AI is already table stakes. The interesting question shifts from “are you using AI?” to “are you using it well?”
The 64% stuck in “experimenting” or “tactical tasks” will either level up or fall behind this year. The 10% with AI embedded in workflows will pull further ahead. Expect a shakeout where AI-mature teams poach talent from AI-immature ones.
My prediction: By the end of 2026, “AI-assisted” will disappear from job descriptions because it will be assumed. If you’re not using the latest crop of AI, you’re not marketable.
But data modeling is still a thing.
2. The Data Modeling Crisis and Semantics
89% reporting pain points of some sort - lack of clear ownership, feeling pressure to move fast, etc. Only 5% using semantic models. Something has to give.
Two possible paths:
Path A: Semantic and context layers go mainstream. AI is making semantics mainstream.
Path B: AI generates models on the fly. Who needs a semantic layer when LLMs can interpret messy schemas? At the rate models are progressing, nothing would surprise me at this point.
I think Path A happens first, then Path B eats it in 2027-2028. The models are getting crazy good.
Prediction: Semantic layer and context tooling have a breakout year. Of course, the training will need to be there for teams to fully capitalize with these technologies. Interestingly, the survey shows a lot of demand for both data modeling training, and semantic/ontology training, both at 19% each.
3. Orchestration Gets Consolidated or Abandoned
20% with no orchestration across all company sizes is unstable. These teams are either:
Running on vibes and manual processes
Using something not captured in the survey (cron, something else)
About to have a very bad incident
Meanwhile, Airflow and cloud-native orchestration (also Airflow) dominate. Interestingly, Dagster at 12% in small companies vs. 2.6% in enterprises suggests the next generation of tooling is coming from the bottom up. Airflow’s dominance is eroding but very slowly.
Then there’s orchestration for AI agents, which remains to be seen how it plays out.
Prediction: Either Dagster/Prefect breaks into enterprise, or “orchestration” as a category gets absorbed into platforms (Databricks, Snowflake, dbt Cloud, etc.).
4. The Lakehouse vs. Warehouse War Ends in a Draw
44% warehouse, 27% lakehouse, 12% hybrid. Does this mean that by 2027, the share will be 35% / 35% / 30%? Maybe. As Snowflake and Databricks converge on feature parity, “Lakehouse” ceases to be a differentiator and becomes the norm. Iceberg adoption will be interesting to see unfold.
Latin America’s 40% adoption of lakehouses is a leading indicator, and I’d love to dig into that figure further. Is this a greenfield adoption, sort of like how some countries skipped copper landlines and went straight to fiber-optics and wireless?
Prediction: By the end of 2026, the “warehouse vs. lakehouse” debate feels dated. The answer is “yes.”
5. Leadership Becomes the Bottleneck Everyone Talks About
If we slice the data by role, 22% of data engineers cite “lack of leadership direction” as a major issue. It’s nearly as high as legacy tech debt (26%). Combined with “poor requirements” (18%), these all indicate organizational dysfunction.
Of course, with every company wanting to do AI, I suspect leadership will need to look in the mirror if it wants to succeed. Same as it ever was, right?
Prediction: 2026 sees more content, training, and conversation about the intersection of data leadership, stakeholder management, and organizational design alongside data engineering. The problem is too big to ignore.
Or we just replace people with AI bots, which I’m sure is leadership’s ultimate fantasy.
Or…we just kick the can down the road for another year, as we’ve done for decades.
Lastly…Bonus Trend
Some teams won’t make it, cuz ineffective leadership.
While I’m surprised that most teams expect their team size to either stay flat or grow, 7% expect it to shrink. But dig into that 7% a bit more - 30% of cite “lack of leadership direction” as their bottleneck. They’re not shrinking because of AI or efficiency, but because they never got organizational buy-in. That’s tragic.
2026 will see more data teams dissolved, merged into engineering, or outsourced. The survivors will be teams that proved business value, not just technical capability.
Data engineering in 2026 is less about picking the right tools and more about building the organizational muscle to use them well. The teams that figure this out will separate from those that don’t.
2026 Practical Data Community State of Data Engineering: Interactive analysis tool + dataset
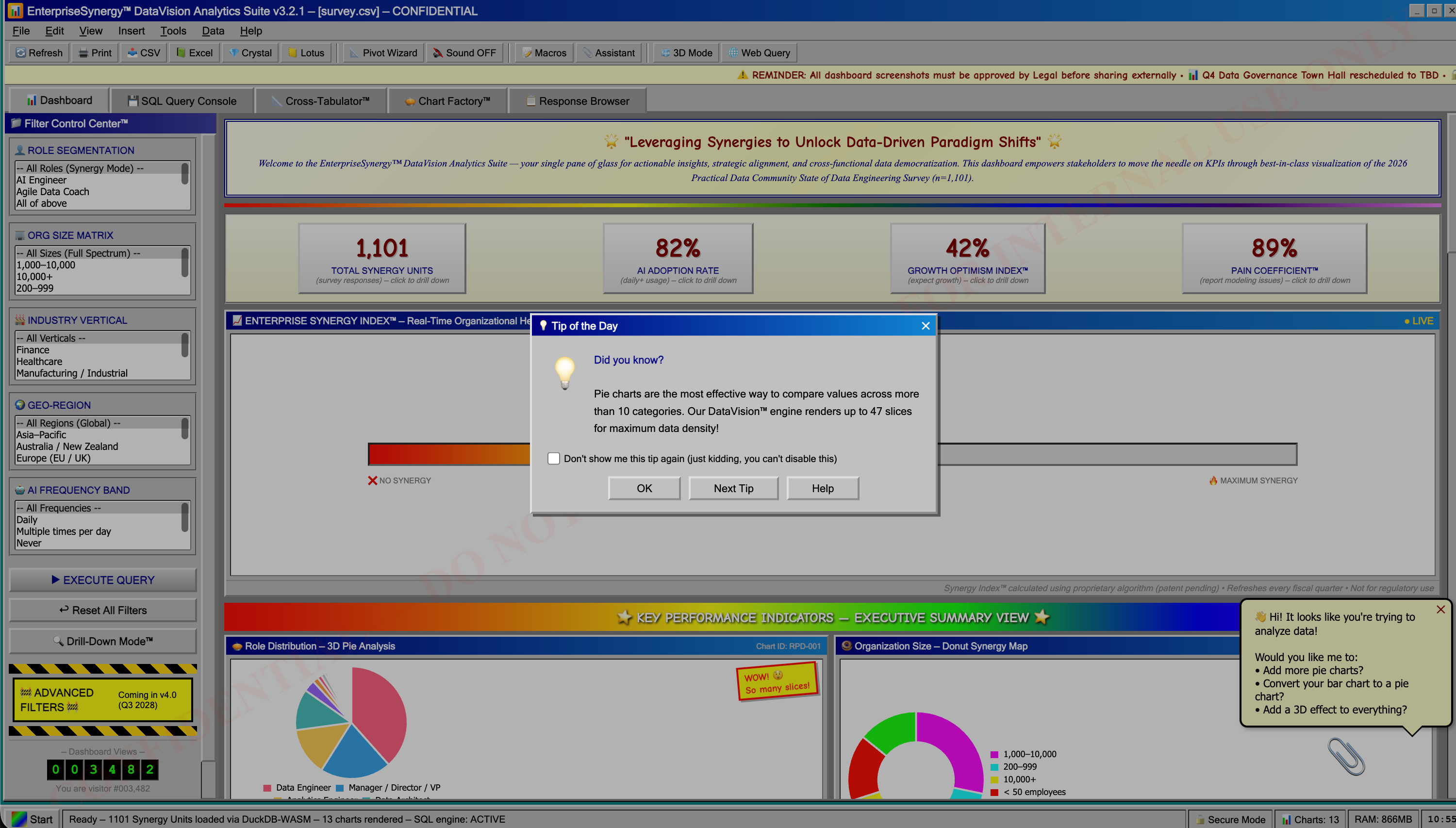
The survey has an alternative super corporate BI tool, complete with 3D donut charts and speedometer charts, exports to Lotus and Crystal Reports, and more. Cutting edge BI tooling at its finest.
As a sidenote, making the above tools was a lot of fun. Both involved plopping the csv dataset into Cursor, giving it some vague instructions, and having it go to town.
Here’s how I made the corporate BI tool in Cursor. I actually made this during a podcast too, watching the AI agent create the entire tool in around 30 minutes. It’s crazy how good the AI coding tools are getting.
Also, listen to this as a podcast. Available on Spotify, Apple, and wherever else you get your podcasts. Please support the show with a review. It means a lot.
Have a great weekend,
Joe
As you saw in the survey, data modeling is a big challenge, and also a massive opportunity. One company that truly understands data modeling is Ellie.ai.
Ellie makes data modeling as easy as sketching on a whiteboard, so even business stakeholders can contribute effortlessly. By skipping redraws, rework, and forgotten context, and by keeping all dependencies in sync, teams report saving up to 78% of modeling time.
Get the foundations right for your data stack with Ellie.ai

Thanks to Ellie.ai for partnering on this newsletter.
Awesome Upcoming Events
Confluent Undercurrent. San Francisco. Me. March 26th…we’ve got something special in store for data engineers. Stay tuned for more details.
Some friends of mine are doing these events:
SLC
Kyle Nesbit (CEO of Credible, ex-Google) will talk about Giving Data Value to AI at the Utah MLOps Meetup on Tuesday, February 24th.
Mountain View
My good friend Demetrios and the ML Ops community are doing an amazing event on Tuesday, March 3rd in Mountain View, at the Computer History Museum.
Coding Agents: AI Driven Dev Conference.
But wait, there’s more!

Cool Videos and Reads
I sat down with Paul Dudley (CEO) and Ricky Thomas (CTO) from Streamkap to catch up on where the world of streaming data is heading. And things have changed fast since we last spoke!
We dive into vibe coding and how AI is radically accelerating how we build software (I even share a story about building a data analysis tool in an hour). But the real meat of this conversation is about the intersection of streaming data and AI agents. Everyone is building agents, but without real-time context, they’re flying blind. We discuss why streaming is a missing link for agentic workflows, the shift from dashboards to automated decision-making, and why SaaS companies are racing to build walled gardens around their data.
We also get into the nitty-gritty of the UK vs. US tech markets, the resurgence of PR in the AI era, and Streamkap’s upcoming move into the Snowflake native app ecosystem.
Here are some things I read this week that you might enjoy.
America Isn’t Ready for What AI Will Do to Jobs
The rise of the 9-to-5 influencer
Something Big Is Happening — matt shumer
Why Vampires Live Forever | Machiel Reyneke
Opinion | I Left My Job at OpenAI. Putting Ads on ChatGPT Was the Last Straw. - The New York Times
VC-Backed Startups are Low Status - by Michael Dempsey
Private-equity barons have a giant AI problemDOMO DRAMA: Rehab & Fight Clubs
Find My Other Content Here
📺 YouTube - Interviews, tutorials, product reviews, rants, and more.
🎙️ Podcasts - Listen on Spotify or wherever you get your podcasts
📝 Practical Data Modeling - This is where I’m writing my upcoming book, Mixed Model Arts, mostly in public. Free and paid content.
The Practical Data Community
The Practical Data Community is a place for candid, vendor-free conversations about all things tech, data, and AI. We host regular events such as book clubs, lunch-and-learns, Data Therapy, and more.
I think we’ll see an instance where AI generated code causes something that may lead to legal ramifications and the entire industry taking a look at how it assigns blame in similar cases
Well articulated