
Is Kimball Still Relevant?
Joe's Nerdy Rants #10 - Weekend reads and other stuff

Is Kimball Still Relevant?
“This feels like a waste of time. People like this have no answer to how the Kimballs and Star schema design change in the face of the columnar storage and unlimited compute . It's sad, it's like your Grandfather trying to relive his glory days when the world has moved on.” - a keyboard warrior commenting on my data modeling show w/ The Seattle Data Guy1
We exist in an embarrassment of riches when it comes to tooling and tech. There’s a tool to address practically every problem out there. Tools and raw compute power are no longer a challenge for most workloads. Functionality and power are table stakes. Which, I guess, brings us back to self-actualization as an industry.
You’d think that since we've got all of the tools and horsepower to crunch massive amounts of data, we’d have moved on from discussions of delivering “business value” with data. Yet discussions about value are more prevalent than ever, data teams are on the chopping block, and I’m unsure we’re getting more value from our data than when my good friend (he calls me his little brother) Bill Inmon popularized the data warehouse in the late 1980s.
Continuing from my rant last week, Data Modeling - What if We Just Burn it All Down? I’d like to address an example of the rot pervading the data industry - the debate of whether Kimball’s dimensional model is dead. As this argument goes, because we can throw our data into columnar storage and throw compute at querying data, the notion of modeling data is tedious and a waste of time. I can sympathize with this, having heard this argument and seen the consequences countless times. The argument is clear. What are the consequences? Often, it means doing dumb things more quickly than you’d like. A lack of a data model is still a data model, albeit a crappy one. And users can tell and smell the consequences of this. It smells like a NYC dumpster on a fine summer afternoon. It stinks. Cloud data warehouses are full of incomprehensible tables, and “the business” is confused about how to leverage this data. The business often reverts back to Excel, and you can guess what happens next. But hey, you can query data more quickly, right? Sadly for you, the rest of the biz is now back on Excel, and your days are numbered. You just don’t know it.
So what does this have to do with Kimball? First, it’s interesting in itself that people equate data modeling with Kimball, often ignoring the universe of other data modeling approaches out there. This should be the first clue that data modeling knowledge is limited these days.
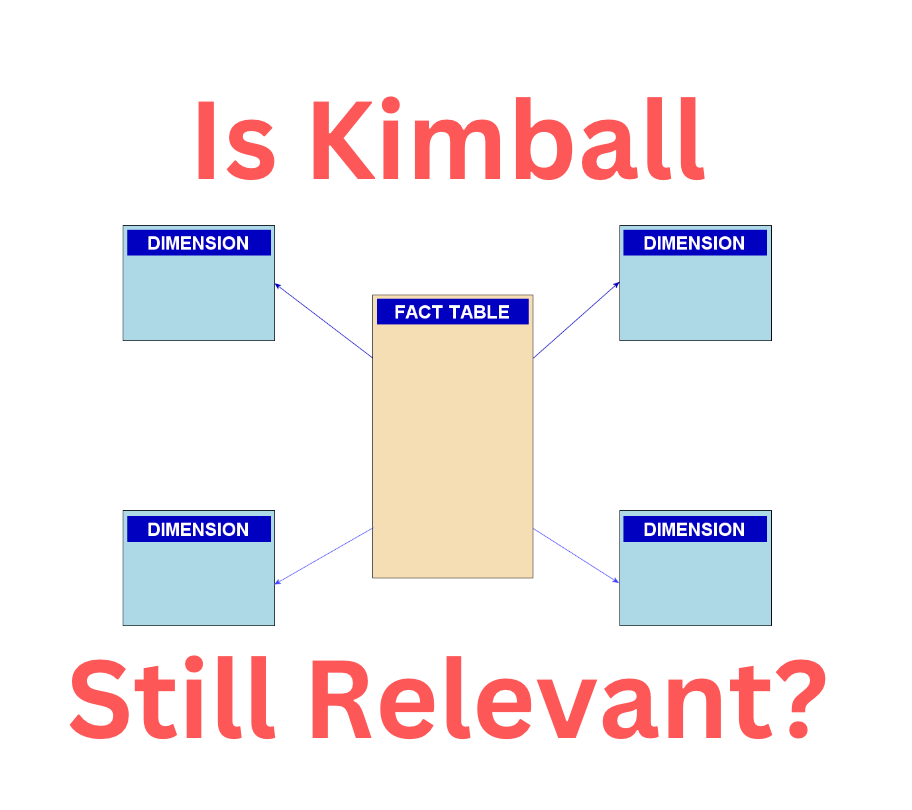
Here’s a little review of Kimball data modeling. Ralph Kimball popularized the dimensional modeling approach, in which you model your business logic as facts and dimensions. From his seminal book, “The Data Warehouse Toolkit,” “A fact table is the primary table in a dimensional model where the numerical performance measurements of the business are stored.” “Dimensions tables contain the integral companions to the fact table. The dimension tables contain the textual descriptors of the business.” That’s it. Notice there’s no discussion of technology or tools. The Kimball approach is a very simple way to think about how the concepts and processes of your business translate into a data model suitable for presentation in reports and analytics.
It’s worth noting that the terms fact and dimension were first used back in the 1960s, and it’s arguable that the original dimensional model was introduced by IRI and AC Nielsen back in the 1970s. These were the enigmatic analytics companies in their era, and even back then, they understood the power of sensible and easy-to-understand data models.
Second, the disturbing trend I’ve seen is that as we replace data modeling with fancy tools, we’re drifting from our ability to think and reason about data. The argument against Kimball is column stores are terrible with joins, so it’s best to reduce the number of joins for query performance. Fair enough. This also ignores the improvements to popular data platforms like BigQuery and Snowflake to optimize for joins. Data platform providers aren’t stupid, they listen to their customers, and it turns out that joins are popular. But if joins are performance-inhibiting, you’ll find an approach that works.
Many data practitioners put performance ahead of all else. This is exactly backward. Data modeling isn’t only about assembling data to be quickly queryable. Performance is great, but this is supposed to be addressed last during physical data modeling, not at the start. But all too often, people start with performance considerations in mind, ignoring the higher-level practices of conceptual and logical modeling. The trade-off of a physical-first approach to data modeling is a loss of fidelity, understanding, and business value impact.
Is Kimball still relevant? Absolutely. It’s a battle-hardened, time-tested way to model data for analytics. Is it the only way to model data for analytics? Definitely not. There are other approaches like Data Vault (often used alongside Kimball), one big table, just a bunch of tables, “query-driven development” (my new term), and traditional data marts. To say Kimball is irrelevant because of columnar storage and unlimited compute is a dangerously ignorant statement. It is like saying because cars have more horsepower, you don’t need to know how to drive a car. Sadly, this mentality is becoming more common in our industry2.
Here’s the deal. If you’re aware of the various data modeling approaches and can pick the right approach for your particular situation, terrific. You’re a competent and thoughtful professional. To completely ignore data modeling is professionally negligent, and I’ll argue you’re unfit for your job. We can do better as an industry. Don’t burn down data modeling just yet…
Listen to the audio clip above on this topic, which is also my 5 Minute Friday on Spotify.
Cool Weekend Reads
Hope you all had a great week.
Here are some cool things I read this week…
Tech, AI & Data
That happened. Also, see the next article ;)
When Open Becomes Opaque: The Changing Face of Open-Source Hardware
Companies (Adafruit)
“…recently some open-source hardware companies have either gone closed-source on products, are in process of going closed-source, are delaying the release of files/source code, or require NDAs to obtain the software for an advertised-as open-source hardware & OSHWA certified product. Many of the formerly open-source hardware and software based companies were built on open-source, what will this mean for the users, and open-source community going forward?”
Open-source-washing is a thing. I hope professionals start pushing back on companies claiming to do open source while doing something entirely self-serving.
Timeseries with PostgreSQL (Alex Plescan)
Time series data is popular, and so is Postgres. Find out how to make these work together.
Why AI detectors think the US Constitution was written by AI (Ars Technica)
Were the Founding Fathers time travelers or AI?
Business & Startups
The dirty little secret that could bring down Big Tech (Insider)
“Capitalism is supposed to allow competition to foster innovation and choice; monopolies quash all that so a few people can get rich.”
I read a study a few months ago discussing how massive VCs basically subsidized startups for years in order to undercut on price, with the expectation of taking over the market at some point. This article is gold if you want some examples of this in action.
In Search of Van Halen's Brown M&Ms (Snack Stack)
“Back in the ’80s, the rock band Van Halen had a long list of demands in their contract rider. Just endless picky stuff about the stage setup and the lighting and all kinds of technical details, along with various food mandates. The wildest thing, by far, was a line item that read, “a bowl of M&Ms, with all the brown ones removed.” Total rock star move, a real “We have enormous egos and don’t you forget it” situation.”
“… So just as a little test, in the technical aspect of the rider, it would say "Article 148: There will be fifteen amperage voltage sockets at twenty-foot spaces, evenly, providing nineteen amperes ..." This kind of thing. And article number 126, in the middle of nowhere, was: "There will be no brown M&M's in the backstage area, upon pain of forfeiture of the show, with full compensation."“
The article is worth reading because 1) the Van Halen rider story is a classic urban legend 2) you understand that this urban legend is pure marketing genius.
Social media is too much for most of us to handle (The Register)
Long ago, my dad predicted most people would eventually leave social media. He argued people would burn out with their lives in public all the time. At the time, I thought he was being a curmodgeon. Now that I see friends leaving social media, he might be on to something.
New Content, Events, and Upcoming Stuff
This week
Monday Morning Data Chat - Dataframe Deep Dive w/ Devin Petersohn (Spotify, YouTube)
In case you missed it…
Monday Morning Data Chat - #134 - Should Your Business Chase Generative AI? w/ Andreas Welsch (Spotify, YouTube)
Monday Morning Data Chat - #133 - Intro to Data Contracts w/ Andrew Jones (Spotify, YouTube)
The Joe Reis Show
Benny Benford - Elevating Data to a Profession (Spotify)
Joshua Bowles - A Wide-Ranging Chat on ML and AI (Spotify)
In case you missed it…
Maya Mikhailov - Cutting Through the BS of AI and Making it Useful in Business and Life (Spotify)
Peter Hanssens - Building Awesome Data Communities in Australia and Beyond! (Spotify)
Upcoming
Monday Morning Data Chat - Why Your BI Team is Your Best Bet for Data Science w/ Dave Langer (Live on LinkedIn and YouTube)
The Joe Reis Show - Lots coming up! Scott Taylor, Kai Zenner, Vin Vashista, and many more….
Events
Joe Reis + dbt roadshow - Atlanta (8/10), Seattle (9/7). More details are coming soon.
DataEngByes. I’ll be on the continental tour in Perth, Brisbane, Melbourne, and Sydney for a couple of weeks. August 2023 (more info and registration)
Big Data London - I’m keynoting. Big up the London Massive. September 2023.
Europe - September 2023 TBA
Dubai - October 2023
India - October 2023
Canada - November 2023
Vegas - ReInvent 2023
More to come…
Thanks! If you mind helping out…
Thanks for supporting my content. If you aren’t a subscriber, please consider subscribing to this Substack.
You can also find me here:
Monday Morning Data Chat (YouTube / Spotify and wherever you get your podcasts). Matt Housely and I interview the top people in the field. Live and unscripted. Zero shilling tolerated.
The Joe Reis Show (Spotify and wherever you get your podcasts). My other show. I interview guests, and it’s totally unscripted with no shilling.
Fundamentals of Data Engineering (Amazon, O’Reilly, and wherever you get your books)
Be sure to leave a nice review if you like the content.
Thanks! - Joe Reis
I normally post and ghost, and avoid drawing attention to comments. But occasionally, I like to highlight areas where I think the industry can do better.
The ironic thing is the people adopting this mentality are often roadkill as more an more data teams are under scrutiny for very…costly…practices.
Great article, while the world of Data Engineering may feel a bit lukewarm on Kimball models as there are some arguments it doesn't scale as well as Data Vault or One Big Table, I feel Kimball is more in use than any other point in time due to being the default way to model data in Self-Service Business Intelligence applications (BI): Power BI and Tableau.
And BI is 10 times bigger in usage than DE, I say that as a DE myself.
I think a argument can be made we're living in era where it is common in a large organisation to use multiple types of data model whereas 10 to 20 years ago you can use only Kimball and you'd be called crazy to question it (though I could be wrong, I was still in school then!).
One overlooked gem is The Kimball Group Reader. Available as a book as a collection of articles from 1995 to 2015. Gives a good overview of Kimball's thoughts in easy to read pieces. I'm currently reading a little bit every day. The Kimball Design tips are also available at: https://www.kimballgroup.com/category/articles-design-tips/